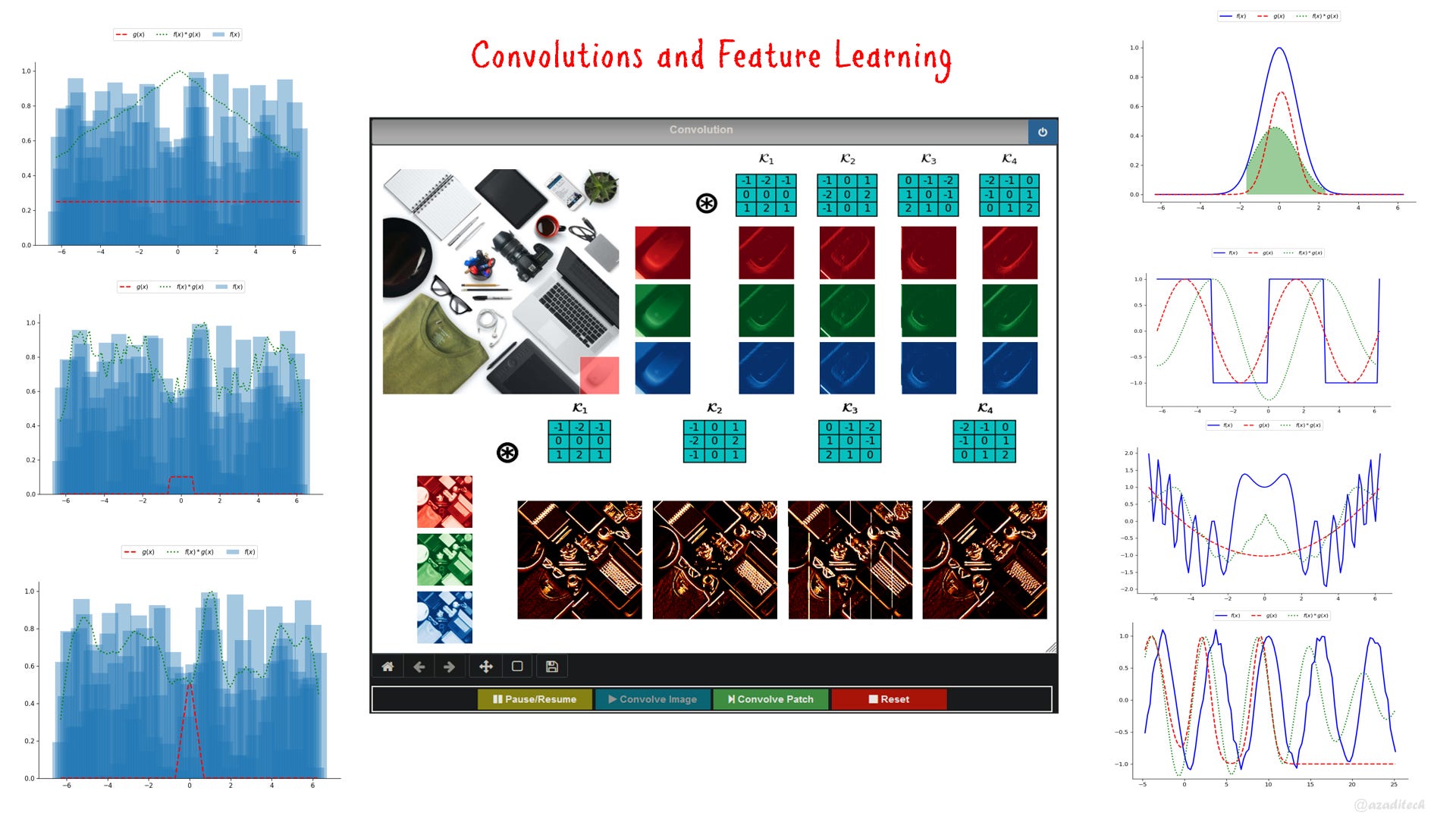
It is a common practice nowadays to construct deep neural networks with a set of convolution layers. However, it was not always like this, earlier neural networks and other machine learning frameworks didn’t employ convolutions. Feature extraction and learning were two separate fields of study until recently. This is why it is important to understand how Convolution works and why it took such an important place in deep learning architectures. In this article we shall explore the Convolution thoroughly and you would be able to understand the concept more deeply with an interactive tool.
]]>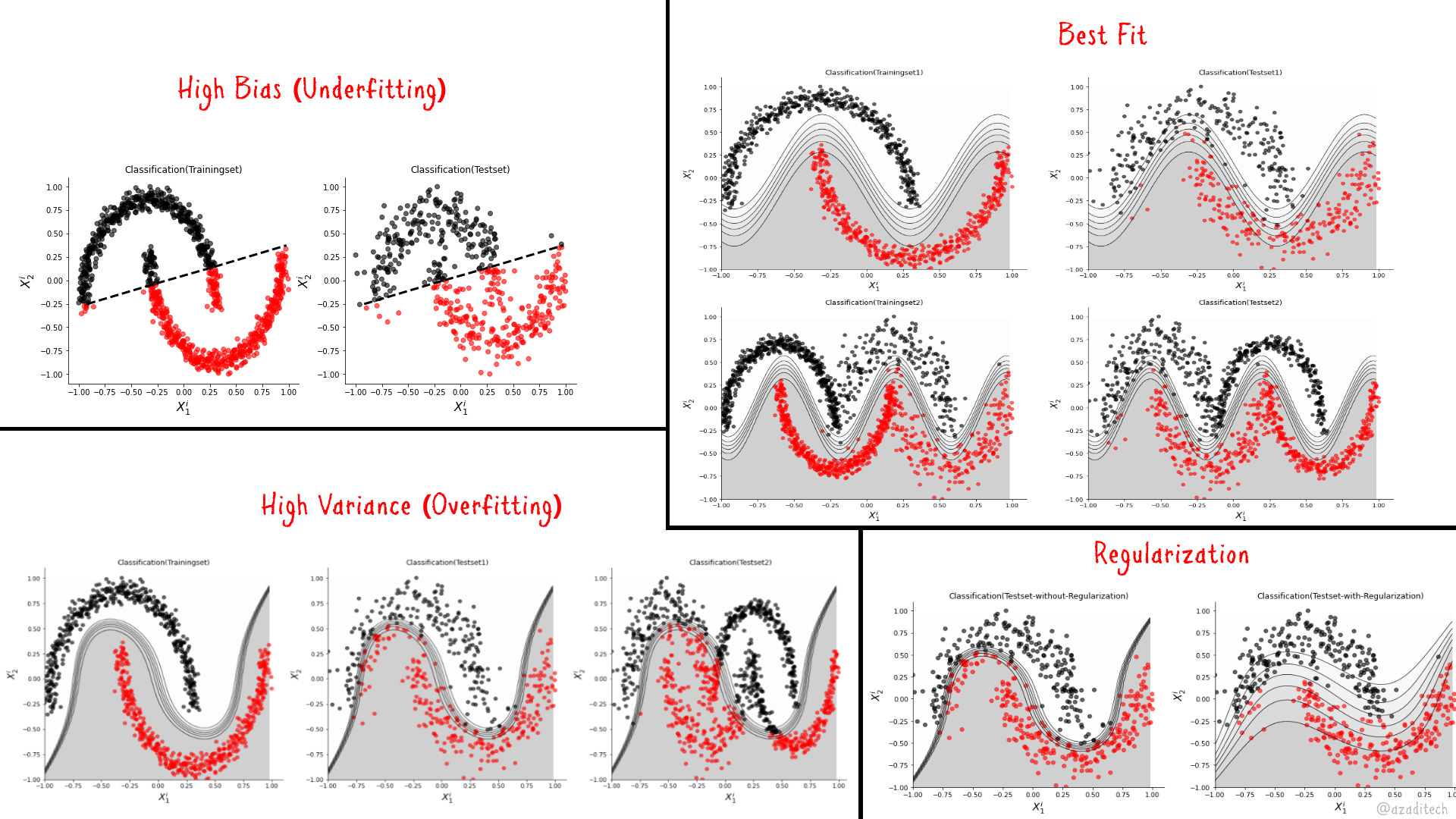
In the previous articles, we have discussed various Machine Learning methods for classification tasks. We have also used terms like Regularization, Overfitting and Underfitting repeatedly. In this article, we shall go through these terms in detail and show how you can circumvent such problems. Furthermore, we shall also discuss various metrics for measuring the performance of a classifier.
]]>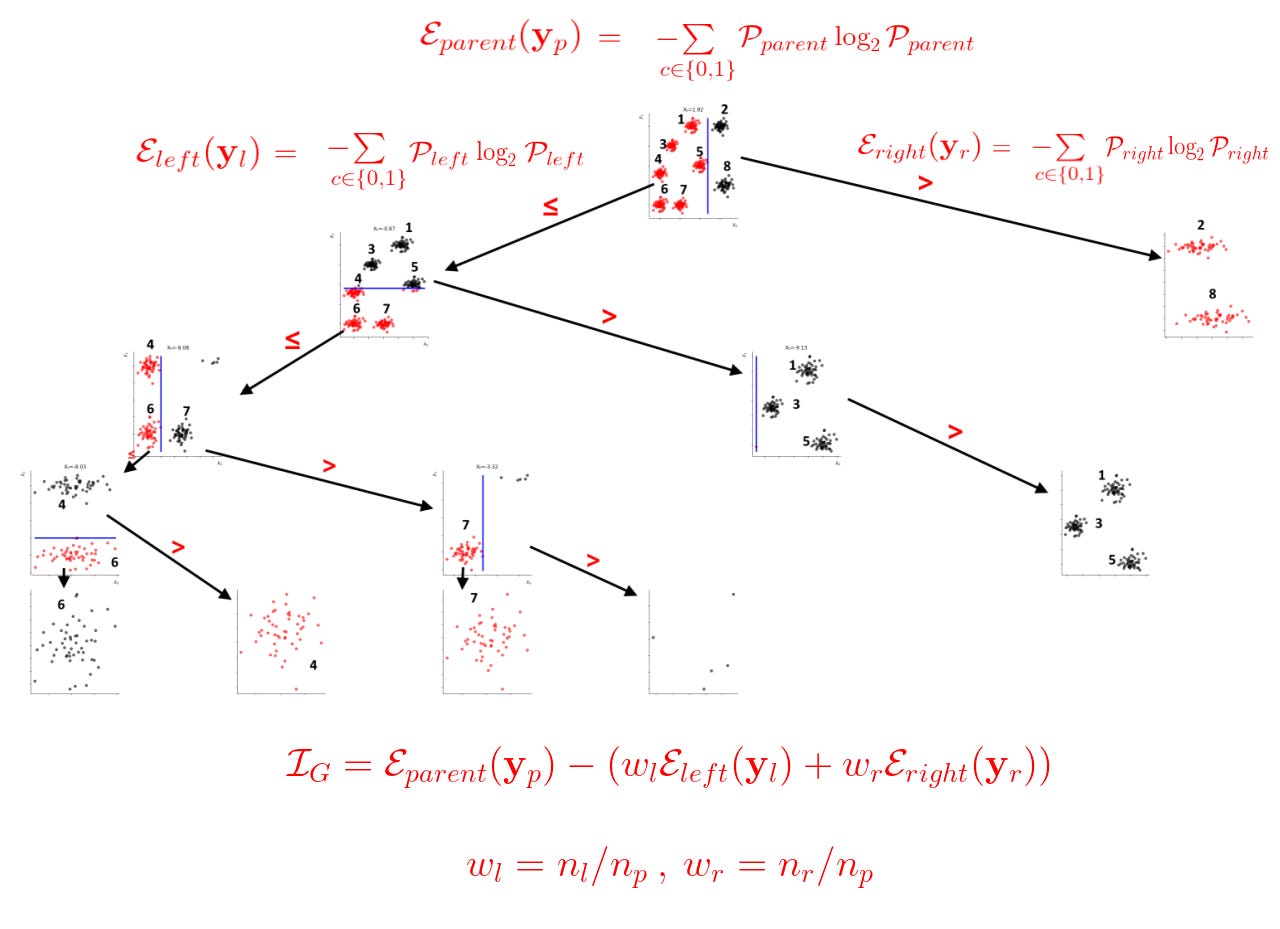
In the previous articles, we have explored the concepts of Regression, Support Vector Machines, and Artificial Neural Networks. In this article, we shall go through another Machine Learning concept called, Decision Trees. You can check-out the other methods from the aforementioned links.
]]>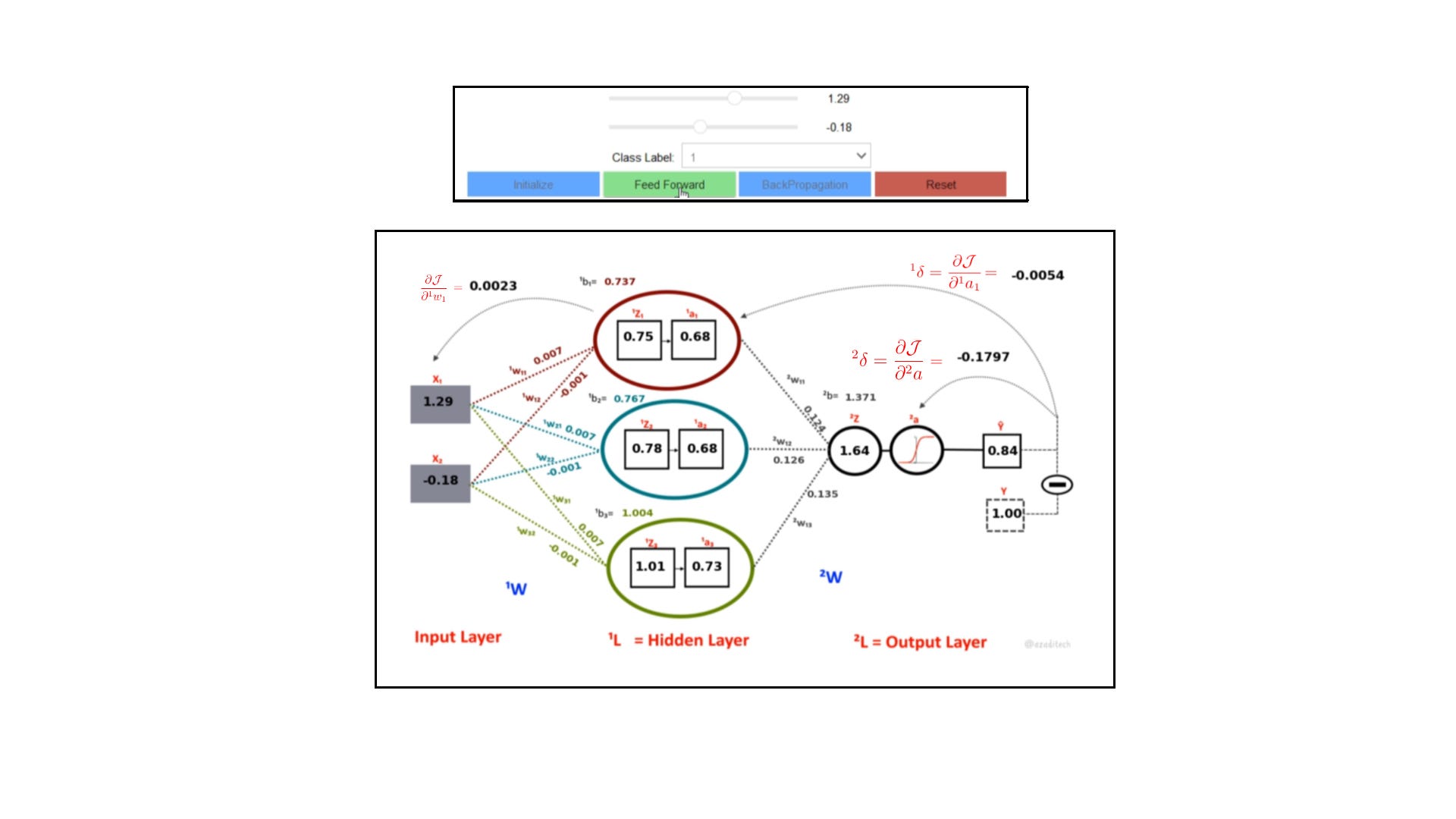
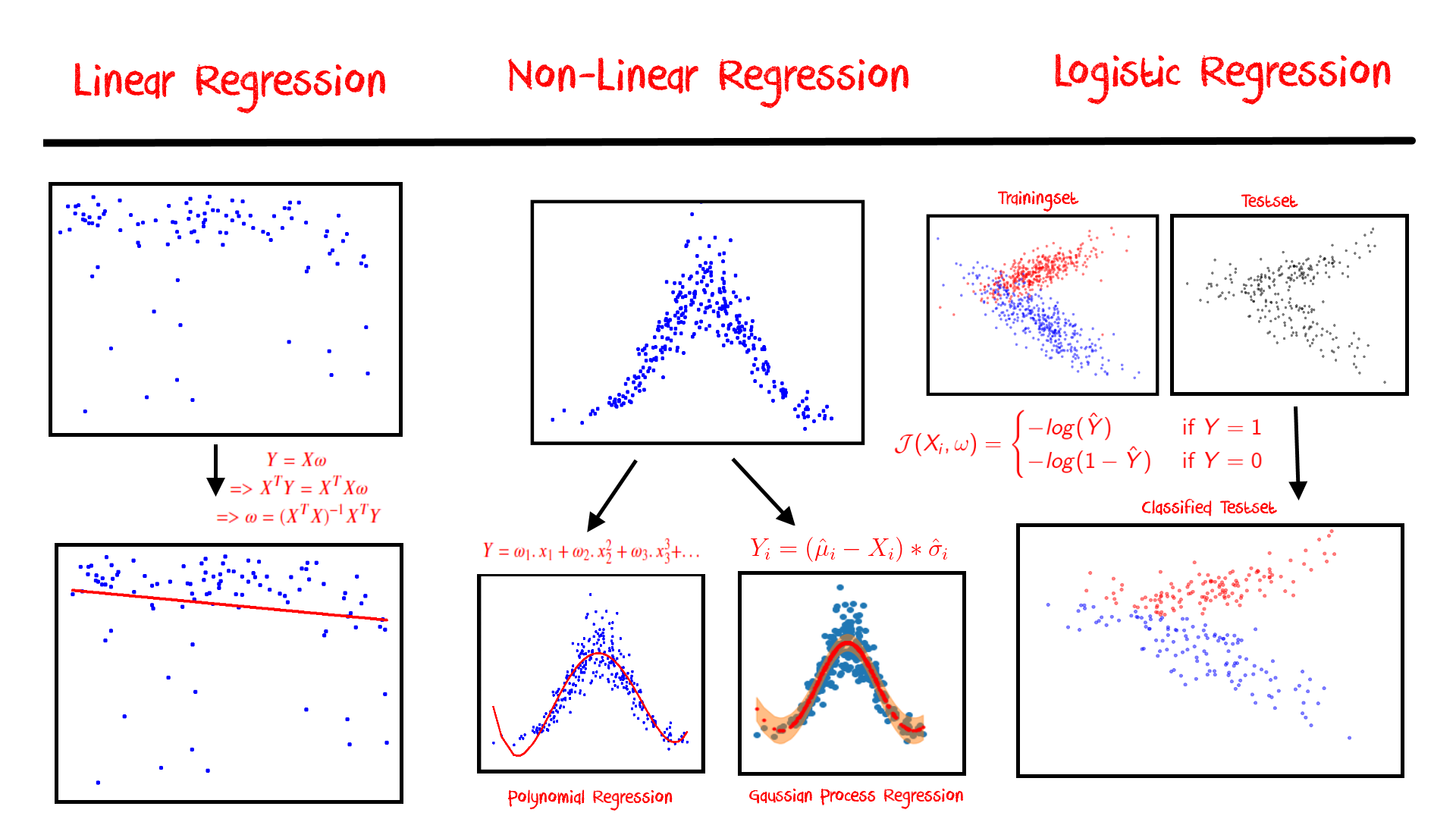
In the previous posts, we have discussed Regression and Support Vector Machines (SVM) as two important methods in Machine Learning. SVM has some similarity to a Regression Analysis, However, there is a method that is a direct descendent of a Logistic Regression. It is called ‘Artificial Neural Network (ANN)’. We shall build an ANN from scratch in this article, and you would be able to understand the concept with an interactive tool.
]]>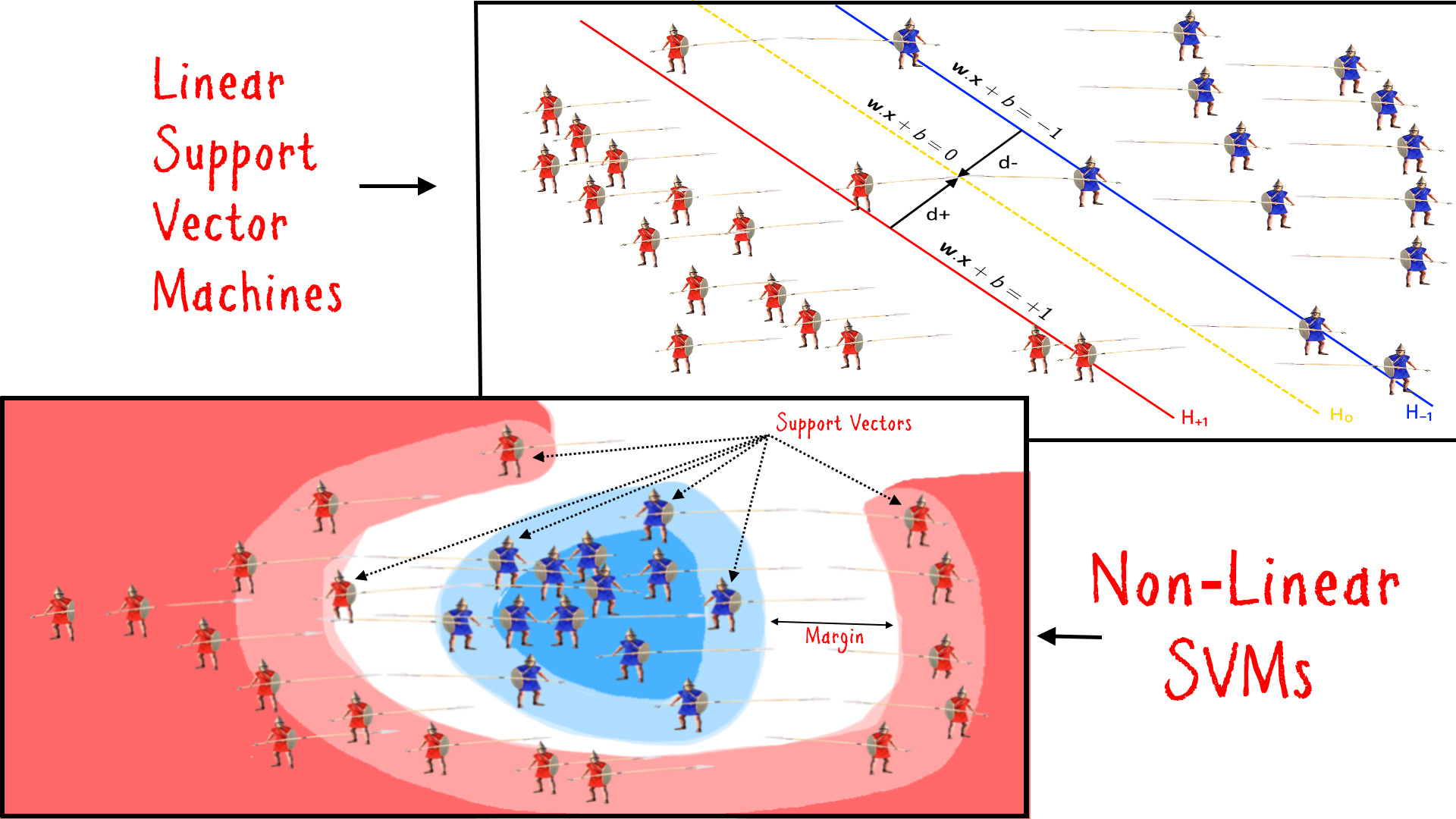
In the previous post we learned about the Regression methods. In this article we shall go through a similar but slightly advanced machine learning method called “Support Vector Machine (SVM)”. Unless you are already familiar, it is advised that you check out the previous post first before reading this article.
]]>
Preface:
There has been growing interest in the introductory posts on the elementary topics in Machine Learning. So, I am writing on such topics in the coming posts starting from this one. This article is mostly self-contained however, it requires basic understanding of linear algebra, and calculus.
]]>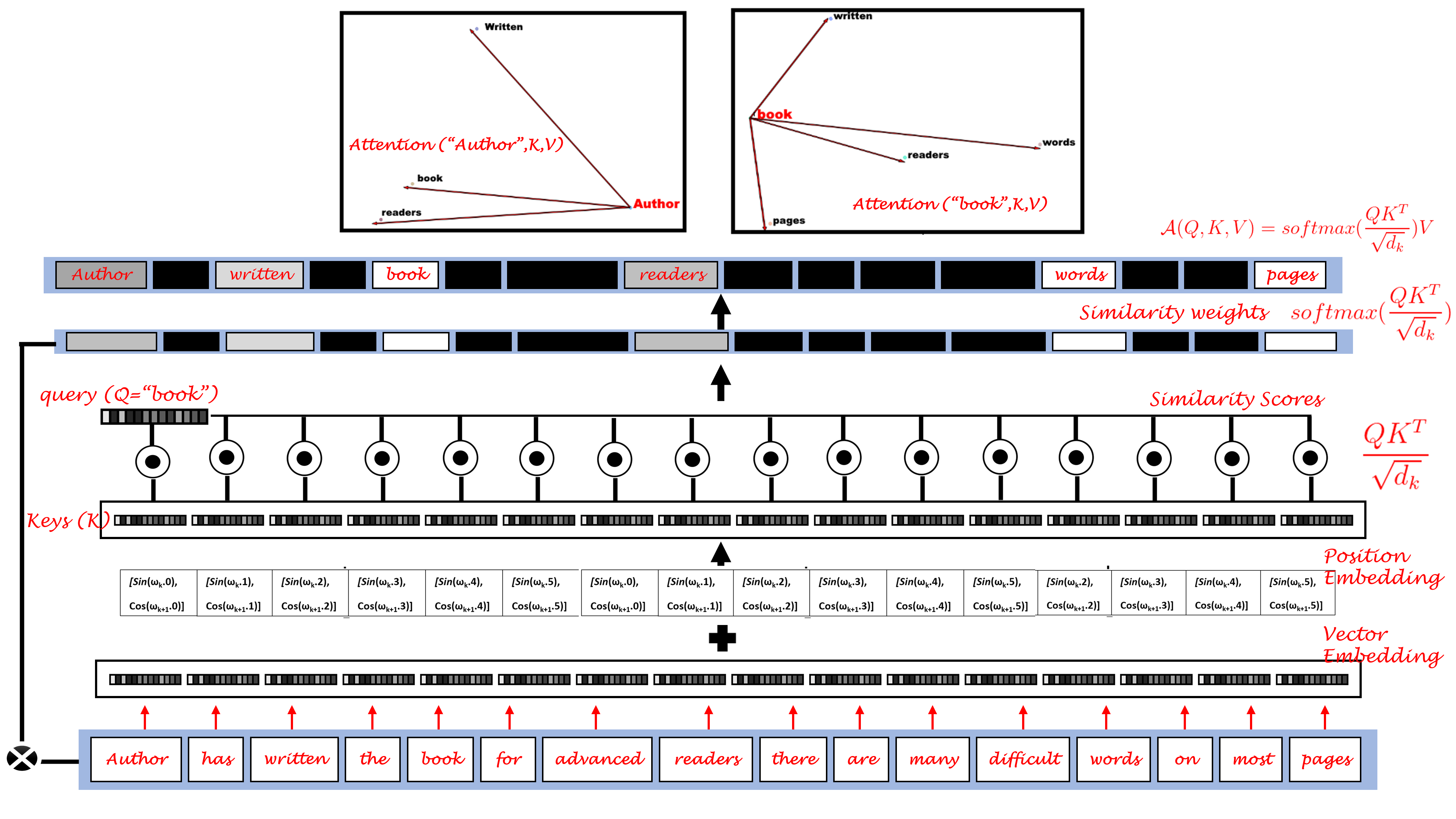
In this article, you will learn about Attention, its computation and role in a transformer network. You will also learn about vector embedding, position embedding and attention implementation in a text transformer. This will make use of concepts, “Transformers” and “Autoencoders”, so, if you would like to learn more about these topics then feel free to check out my earlier posts.
]]>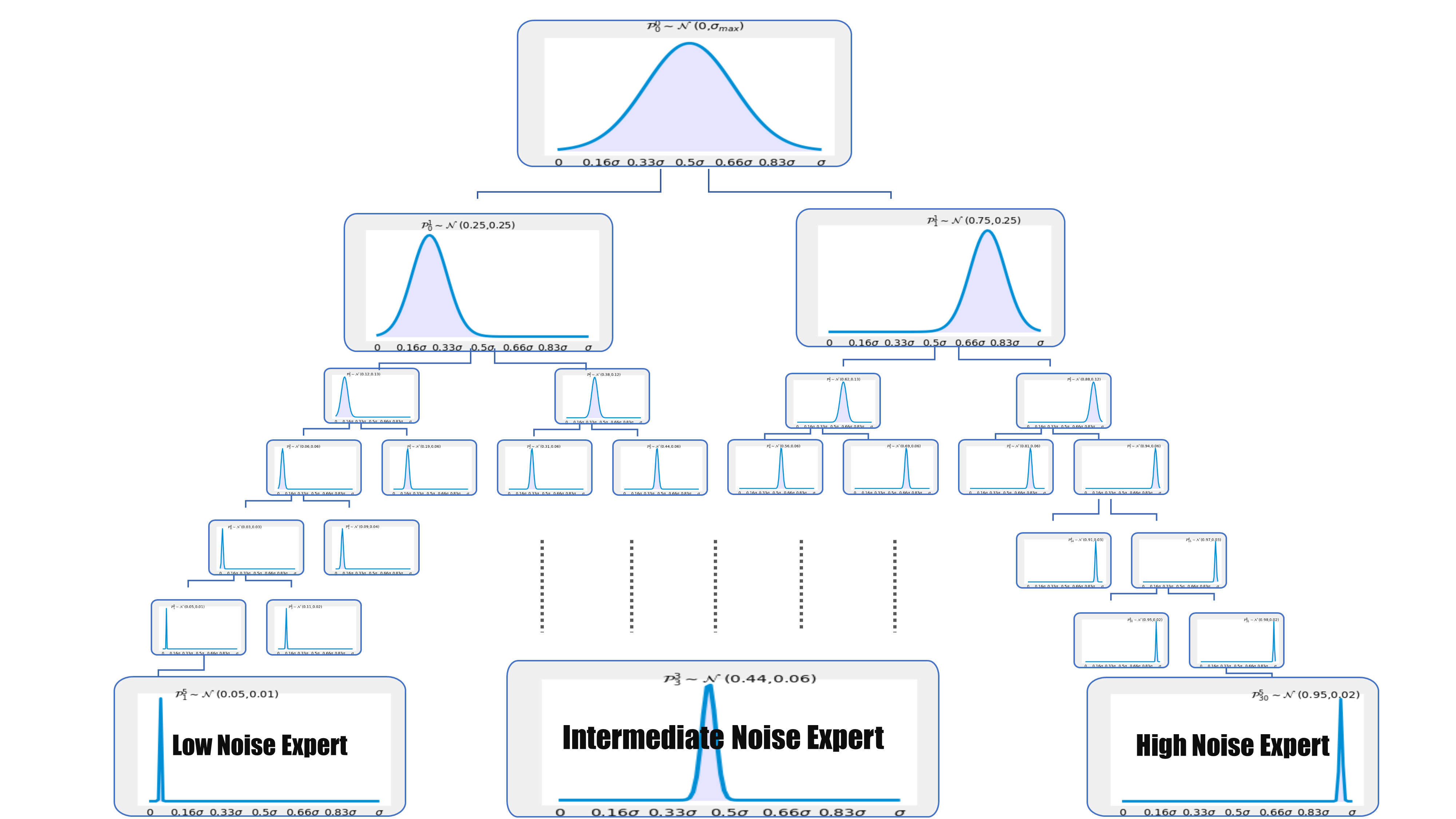

In this article you will learn about customization and personalization of diffusion model based image generation. More specifically, you will learn about the Textual-Inversion and Dream-Booth. This article will build upon the concepts of Autoencoders, Stable Diffusion Models (SD) and Transformers. So, if you would like to know more about those concepts, feel free to checkout my earlier posts on these topics.
]]>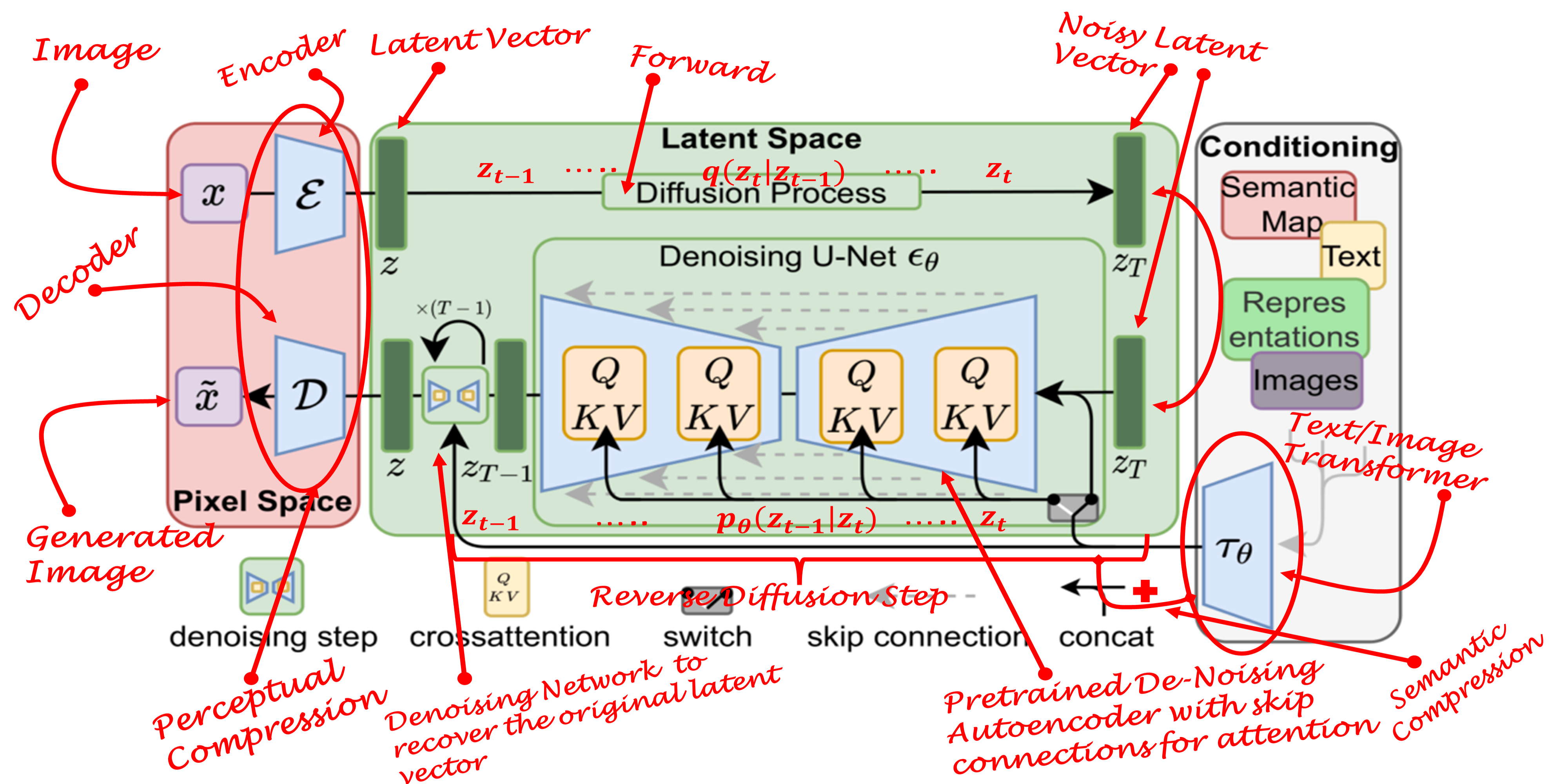
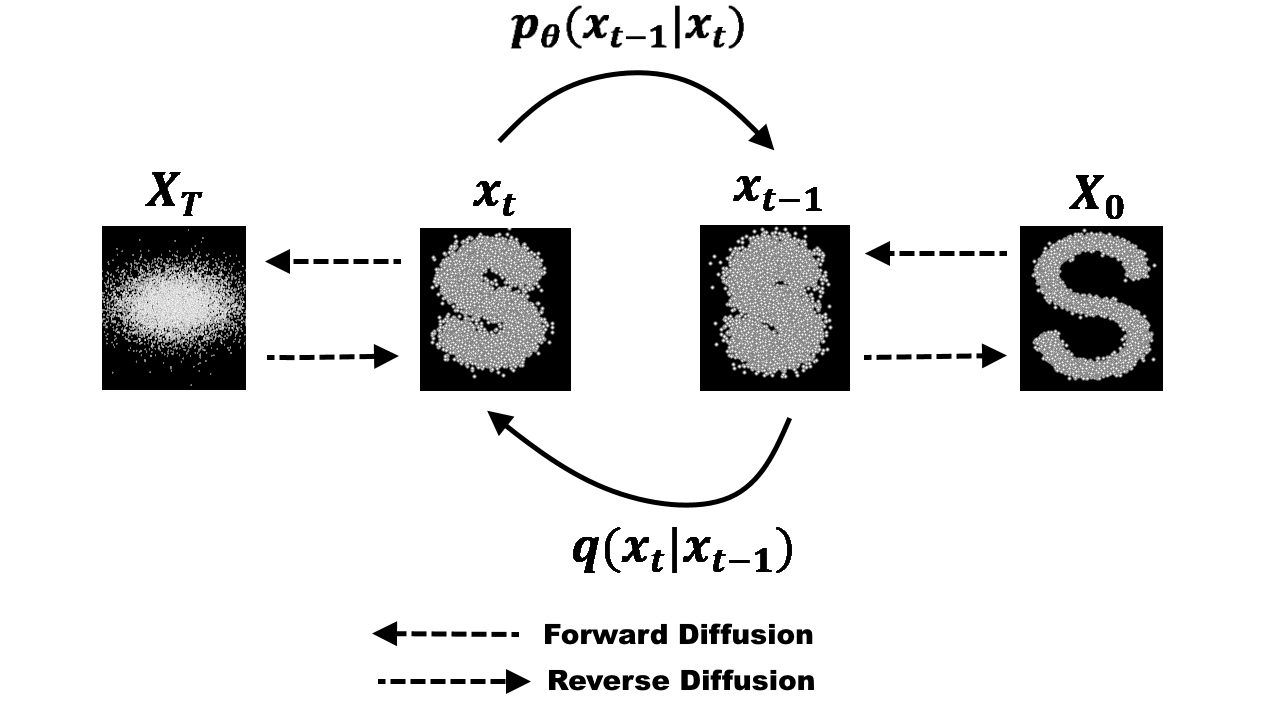
In this article you will learn about a recent advancement in Image Generation domain. More specifically, you will learn about the Latent Diffusion Models (LDM) and their applications. This article will build upon the concepts of GANs, Diffusion Models and Transformers. So, if you would like to dig deeper into those concepts, feel free to checkout my earlier posts on these topics.
]]>
There has been a significant advancement in the field of AI in the past several years. Generative models have been the most successful in the vision domain however, they are built for highly specialized tasks. These specialized learning models require reconstruction or retraining whenever the task is changed. Therefore, the interest in General purpose learning models is increasing. One of such type of models is called Transformers. In this article, we briefly discuss:
What is a Transformer?
What is a Vision Transformer (ViT)?
What are the various applications of ViTs?
How can ViTs be used for general purpose learning?

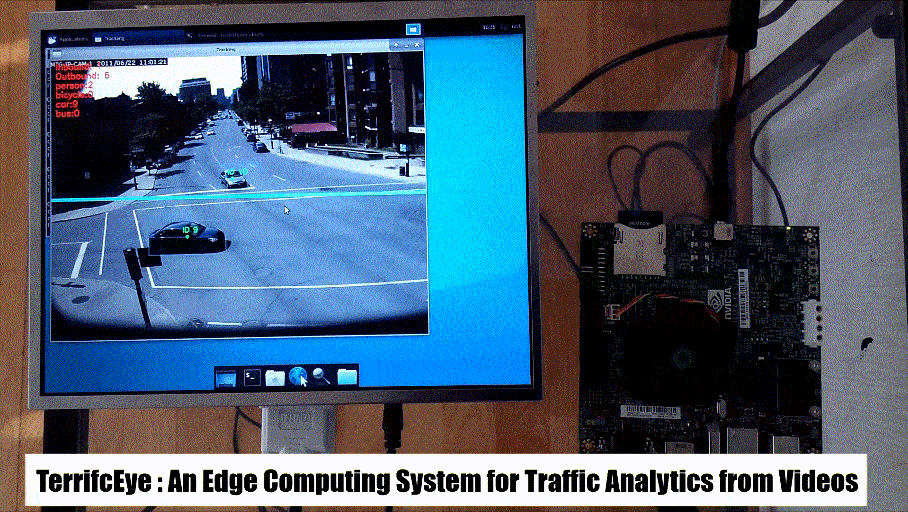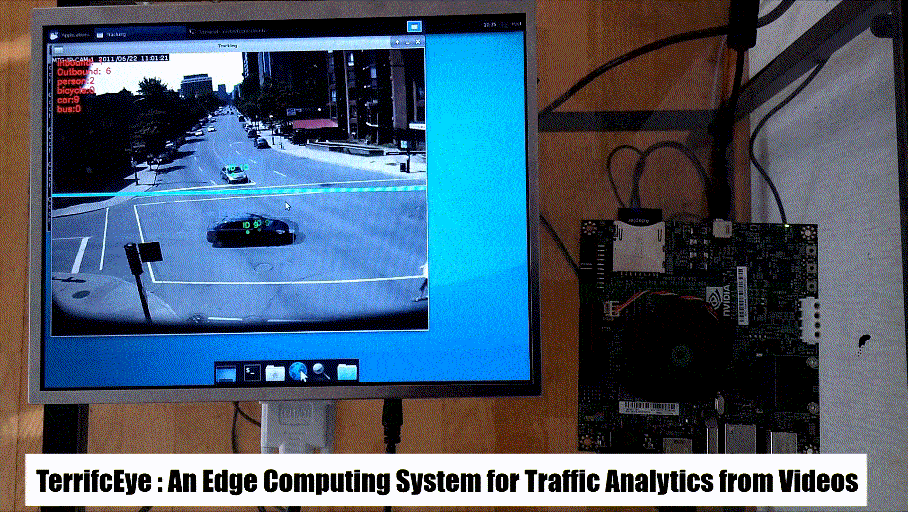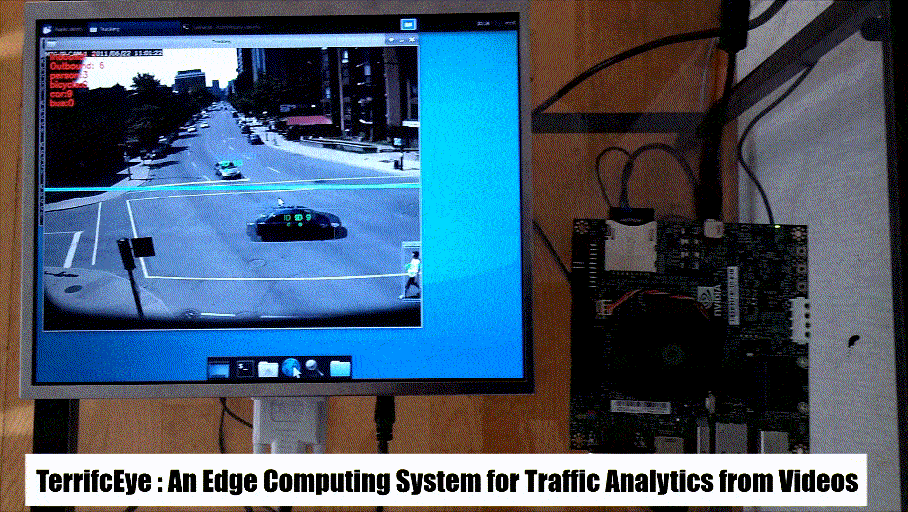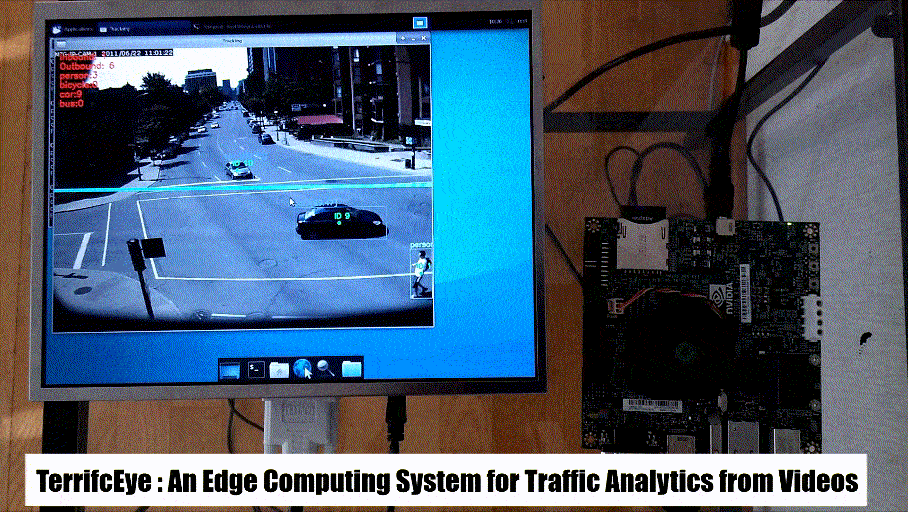
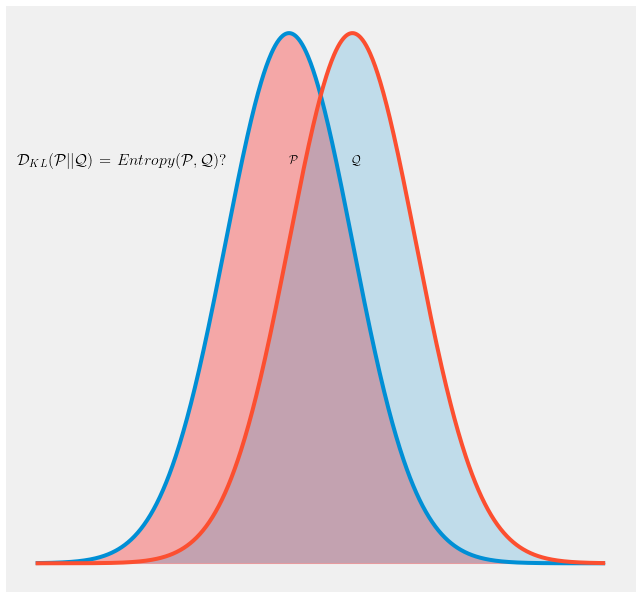
It is a common practice to use cross-entropy in the loss function while constructing a Generative Adversarial Network [1] even though original concept suggests the use of KL-divergence. This creates confusion often for the person new to the field. In this article we go through the concepts of entropy, cross-entropy and Kullback-Leibler Divergence [2] and see how they can be approximated to be equal.
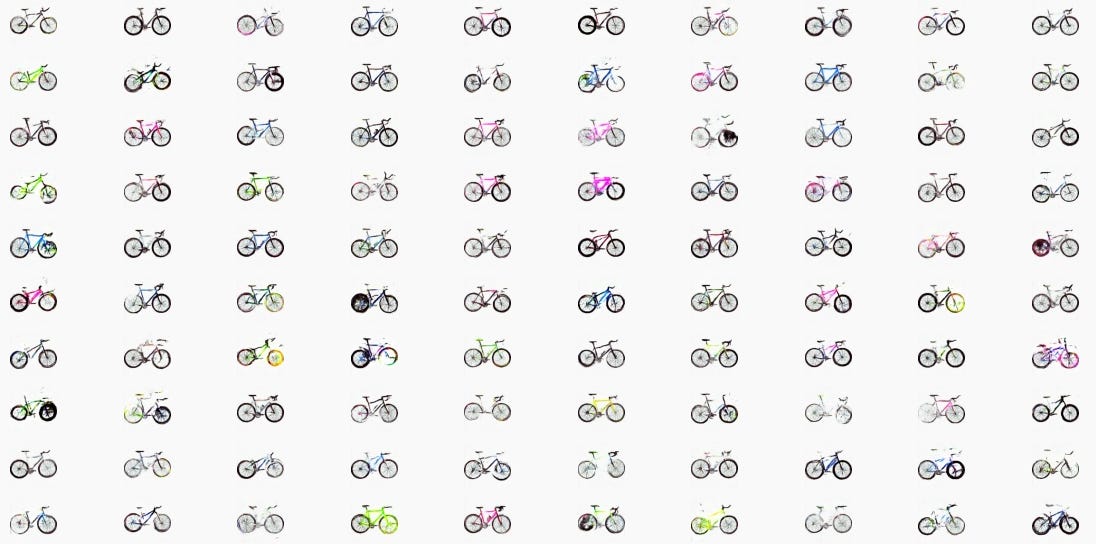
]]>

In the previous tutorial (https://medium.com/mlearning-ai/latent-space-representation-a-hands-on-tutorial-on-autoencoders-in-tensorflow-57735a1c0f3f) we learned about latent spaces, autoencoders and their implementation in TensorFlow. In this tutorial, we shall extend the concept of autoencoders and look at one of the special cases of autoencoders called variational autoencoders.
]]>· Autoencoders
· Variational Autoencoders
· Generative Adversarial Networks
In this tutorial, the focus would be on latent space implementation using autoencoder architecture and its visualization using t-SNE embedding. Before we delve into code, lets define some important concepts which we will encounter throughout the tutorial.
]]>